万方维普检出率差40%?实测揭秘双系统差异
2026-03-25 07:04:02 来源:checkbloc 栏目:查重检测
近期,高校毕业季与职称评审期叠加起来,这俩方面对“人工智能生成内容(AIGC)”的检测成了学术圈关注的焦点。不少作者发觉,同一篇论文在不同检测系统里得到的“AI疑似度”结果差别很大。要探寻这一现象的真实缘由,不做盲目地对“越改更红”做一些修改,而是依据公开学术样本开展了一次交叉对比实测,把主流检测系统的判定差异给给揭示出来了。
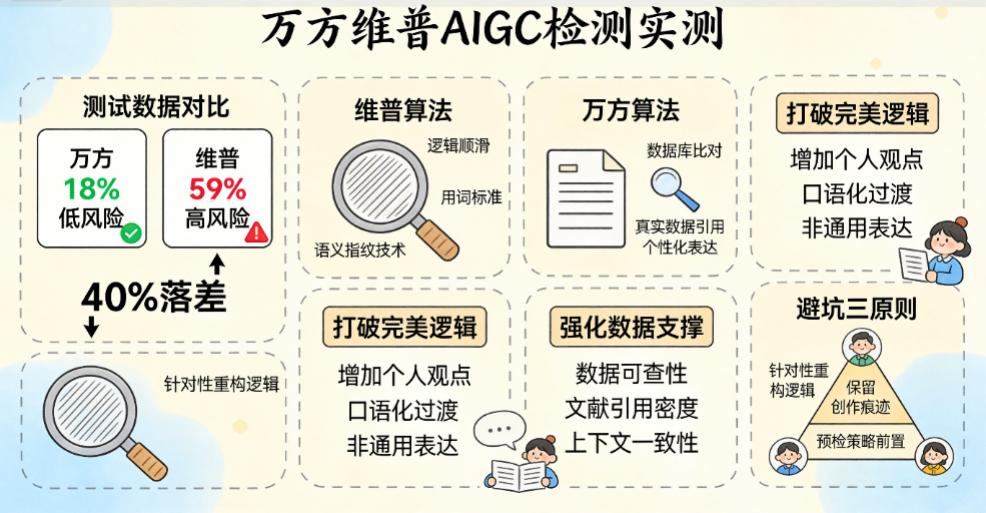
一、实测数据:同文不同命的“40%落差”
本次测试选取了一篇典型的“人机协作”样稿。这篇文章的作者给出了核心观点与数据,接着用它的大模型对初稿进行润色并梳理逻辑,最后经人工再改写。在确保内容本质的不变情况来看,把资料提交到万方数据知识服务平台以及维普中文期刊服务平台进行检测。
万方检测系统给出的AIGC可疑率是18%,属于“低风险”区间;维普系统给出的结果是59%,直接触发“高风险”预警。二者之间相差超40个百分点。这一巨大的反差可不是个例,在理工科实验报告和文史类综述文章里,这种差异尤为明显。这不单是表明某一方系统出错,而是把两大平台底层算法逻辑的根本性分歧给揭示出来了。
二、深度解析:语义指纹与概率预测的博弈
为什么会有如此巨大的判定差异?关键就是对检测技术的侧重点有所区别。
维普系统近年来大力推广“语义指纹”技术。该技术不是靠关键词匹配,而是把文本转化为高维向量,进而分析句法结构的复杂程度以及词语搭配的“机器概率”。文章逻辑过于顺溜、用词太标准,而且缺少人类特有的“跳跃性思维”或者个性化表达,很容易被判定为AI生成。在上述实测当中,大模型经润色后,段落逻辑似乎变得较为刻板,刚好在“指纹”特征之处显现。
万方系统主要关注“数据库比对”以及“上下文一致性”这两方面。其算法会查找海量学术资源里的相似片段,再根据上下文逻辑的断裂情况来判断。万方文章要是保留了大量真实的数据引用、独特的案例描述以及人工写作的非标准化表达,其AI评分往会较低。在实测样本中,这一部分保留原始数据图表分析部分,把万方的风险值有效稀释。
三、避坑指南:拒绝无效“洗稿”,构建合规证据
我们想要改写,让改写后的文本符合人类的书写习惯,保持简洁、清晰、直接、聚焦事实,同时从一般性地阐述,不使用机器的思考,使用一些通俗易懂的文字。
面对双系统间存在差异的标准化标准,传统“同义词替换”、“句式倒装”这类简单降重手段,早已完全失效了,甚至可能破坏语义逻辑而引发新警报。实测数据显示,下面给出三个关键建议:
1.在目标学校或者单位用维普进行写作时,得特别地了解“完美逻辑”,要描述个性化观点、口语化的过渡句,还有有学科特色的非通用表达,这样就能干扰“语义指纹”的识别。若要主要应对各类状况,就得保证数据来源真实且可查,还得提高文献引用的密度与规范性。
2.不管是哪里的系统,都存在一定误判风险,所以要保持创作痕迹。作者要养成读写全文的习,像原始手稿、思维导图之类的,还得和模型对话记录(得证明只是辅助而非代写),还有多次修改的版本存档等,这些都得养成。这些“证据链”在申诉时最为有力。
3.在进行正式的提交之前,得按照所在机构的要求,挑出合适的系统进行预检。万方的结果与维普考核应保持一致,不可颠倒。重要论文时,最好进行双系统交叉自测,把风险值较高的那个当作修改基准。
学术诚信是科研的根基,工具运用得合理这一现象,是时代发展的必然产物。理解检测机制的异同,不能只是零零散地钻空子,得更规范地使用技术,这样才能确保真实学术成果不会被误判,让人类智慧在算法时代依然清晰。
论文查重降重:https://www.checkbloc.com/
Turnitin查重:https://tt.checkbloc.com/
iThenticate查重:https://it.checkbloc.com/
万方查重:https://wanfang.checkbloc.com/
维普查重:https://weipu.checkbloc.com/
本网站部分文章转载自互联网以及作者的分享,如本网站所引用的文章涉及著作权问题, 请您及时通知本站,我们将及时妥善处理。